PinnedPublished inAWS in Plain EnglishTrain, Deploy and Predict Cost-Effective ML Models in AWS CloudServerless Amazon SageMaker Real-Time ML InferenceSep 19, 2021Sep 19, 2021
PinnedPublished inAWS in Plain EnglishIoT/TimeSeries Event Processing using AWS Serverless Services & Managed Kafka StreamingOriginally published at https://medium.com on July 24, 2021.Aug 2, 2021Aug 2, 2021
Leveraging AWS Databricks and AWS Data Analytics Services for Seamless Serverless Stateful…Kappa Architecture , Streaming Table , Delta Live Table, AWS MSK, AWS Kinesis , Databricks Data Apps , Unity Catalog, SQL WarehouseJan 8Jan 8
Published inCloud Data and AnalyticsServerless Full Stack Data Analytics Engineering on AWS CloudServerless Full Stack Development for the modern data analyticsMar 25, 2023Mar 25, 2023
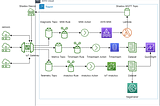
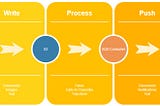
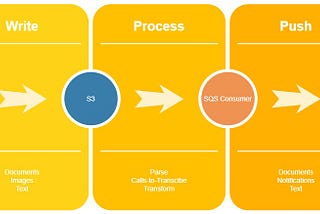
Published inCloud Data and AnalyticsAmazon SQS and serverless DataEngineering workloadsOverviewMar 25, 2023Mar 25, 2023
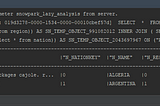
Published inCloud Data and AnalyticsSnowPark -The Scala developer experience on Snowflake Data CloudRunning scala code UDFs at scale inside the Snowflake data CloudJun 27, 2021Jun 27, 2021
Published inCloud Data and AnalyticsCloud-Native integration between Snowflake on AWS and Databricks on GCPEnable data transfers between cloud storage services using vendor-neutral platformsJun 21, 2021Jun 21, 2021
Published inCloud Data and AnalyticsImplementing a Movie Recommendation pipeline using Databricks on Google cloudCloud-Native ML and Data Stacks avoid the vendor lock-inJun 21, 2021Jun 21, 2021
Published inCloud Data and AnalyticsAutoPilot for Machine Learning -Databricks AutoMLEnable the machine learning experiment as a self-service portal.Jun 13, 2021Jun 13, 2021